Hierarchical Cluster Analysis Application on Mental Disabilities Data Using R
Before you read this article, I recommended you to read the basic of cluster analysis in here.
Penderita disabilitas mental memiliki kedudukan, hak dan kewajiban yang sama dengan masyarakat non disabilitas. Sebagai bagian dari warga negara Indonesia, sudah sepantasnya penderita disabilitas mental baik laki-laki dan perempuan tidak diperlakukan diskriminatif. Provinsi DIY memiliki angka penderita disabilitas yang cukup tinggi yaitu 2406 jiwa. dimana penderita disabilitas ini didominasi oleh penduduk dengan jenis kelamin perempuan pada kasus disabilitas mental. Untuk mengetahui tingkat disabilitas di Provinsi DIY, maka perlu metode pengelompokan. Tujuan dari penelitian ini adalah mengelompokkan 78 kecamatan di Provinsi DIY menggunakan analisis cluster menggunakan 5 metode hirarki agglomerative, yaitu Single Linkage, Complete Linkage, Average Linkage, Ward’s, dan Centroid. Analisis cluster merupakan teknik multivariat yang mempunyai tujuan utama untuk mengelompokkan objek-objek berdasarkan karakteristik yang dimilikinya.
Penelitian ini dilaksanakan dengan tujuan yaitu:
- Mengetahui perbandingan metode Agglomerative Hierarchical Clustering (Single Linkage, Complete Linkage, Average Linkage, Ward Method dan Centroid Method) untuk mengelompokkan kecamatan di Provinsi Daerah Istimewa Yogyakarta berdasarkan data AD dan PD penderita disabilitas mental
- Medapatkan metode terbaik dalam mengelompokkan kecamatan di Provinsi Daerah Istimewa Yogyakarta berdasarkan data AD dan PD penderita disabilitas mental.
Adapun manfaat yang diharapkan dari hasil penelitian ini yaitu:
- Dapat menemukan metode yang memberikan hasil cluster terbaik berdasarkan lima jenis metode yang ada di Agglomerative Hierarchical Clustering.
- Hasil dari cluster terbaik diharapkan dapat menjadi bahan evaluasi dan pertimbangan dalam menentukan suatu kebijakan terkait pemenuhan hak-hak penyandang disabilitas mental.
- Secara teoritik diharapkan dapat mengetahui sejauh mana teori-teori yang ada dapat diterapkan ke lapangan atau dunia sesungguhnya.
- Memperluas wawasan mengenai cluster dengan menggunakan beberapa metode yang ada dan membandingkannya.
Dalam penelitian ini, data yang digunakan adalah data sekunder yang diperoleh dari data Dinas Sosial Provinsi DIY dan Website Kependudukan Provinsi DIY, yaitu www.kependudukan.jogjaprov.go.id yang menggabungkan beberapa variabel sehingga agar lebih mudah mempraktikan tutorial dalam artikel ini, anda dapat mengunduh data yang digunakan disini
Definisi Operasional Variabel
| No | Variabel | Definisi | Satuan | |
|---|---|---|---|---|
| 1 | Jumlah Anak Disabilitas (AD) Mental Jiwa | Banyaknya penduduk di bawah usia 18 tahun yang menderita disabilitas mental jiwa. | Jiwa atau orang | |
| 2 | Jumlah Anak Disabilitas (AD) Mental Fisik | Banyaknya penduduk di bawah usia 18 tahun yang menderita disabilitas mental fisik. | Jiwa atau orang | |
| 3 | Jumlah Penyandang Disabilitas (PD) Mental Jiwa | Banyaknya penduduk di usia 18 tahun ke atas yang menderita disabilitas mental jiwa. | Jiwa atau orang | |
| 4 | Jumlah Penyandang Disabilitas (PD) Mental Fisik | Banyaknya penduduk di usia 18 tahun ke atas yang menderita disabilitas mental fisik. | Jiwa atau orang |
Tahapan Penelitian
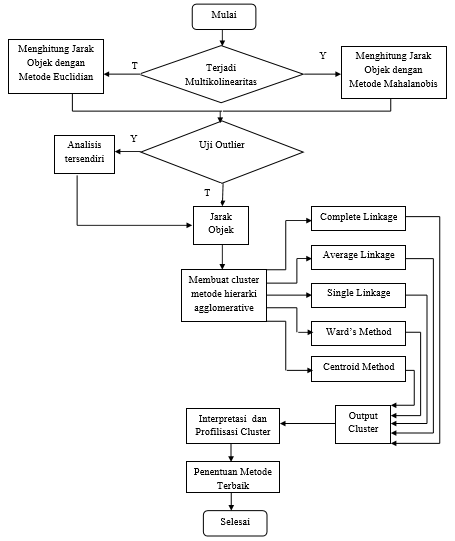
Keterangan :
- Mulai
- Uji Multikolinearitas dilakukan untuk mengetahui apakah antar variabel yang digunakan dalam penelitian saling berhubungan (berkorelasi) atau tidak. Ketika variabel yang digunakan dalam penelitian tidak saling berhubungan (tidak memiliki korelasi) maka selanjutnya dilakukan perhitungan jarak objek dengan metode Euclidean, apabila variabel yang digunakan dalam penelitian saling berhubungan maka selanjutnya dilakukan perhitungan jarak objek dengan metode Mahalanobis.
- Uji outlier dilakukan untuk mengetahui apakah data yang digunakan dalam penelitian terdapat data outlier atau tidak. Ketika data yang digunakan dalam penelitian terdapat data outlier maka data outlier akan dianalisis secara terpisah. Apabila data yang digunakan dalam penelitian tidak terdapat data outlier maka langsung dilanjutkan dengan tahap setelahnya
- Dari langkah 2, diperoleh jarak antar variabel yang kemudian dianalisis cluster menggunakan metode hirarki agglomerative dengan lima metode yaitu complete linkage, average linkage, single linkage, ward method dan centroid method.
- Setelah dilakukan analisis cluster dari lima metode tersebut (complete linkage, average linkage, single linkage, ward method dan centroid method) kemudian akan menghasilkan output cluster yang berupa dendogram.
- Seteleh mendapatkan output cluster berupa dendogram, peneliti kemudian melakukan pemotongan dendogram dengan jumlah tertentu berdasarkan kriteria banyak kelompok yang diinginkan peneliti, seperti 3, 4 atau 5 kelompok.
- Dari hasil pemotongan dendogram kemudian dilakukan interpretasi dan profilisasi hasil cluster kecamatan di Daerah Istimewa Yogyakarta
- Setelah dilakukan interpretasi dan profilisasi hasil cluster kemudian di lakukan penentuan metode terbaik dengan menggunakan korelasi Cophenetic
- Selesai
Tahap Analisis
Meninputkan Data pada Software
Tahapan awal untuk melakukan analisis adalah menginputkan data pada software yang digunakan. Karena data yang digunakan merupakan file .csv maka syntax yang digunakan adalah sebagai berikut :
disabilitas <- read.csv2(file="/folder/Data Disabilitas Mental Jiwa dan Fisik ADK dan PD.csv", header=TRUE, sep=";")
disabilitas
atau dapat juga menginputkan data secara manual dengan syntax seperti dibawah ini :
disabilitas=matrix(c(0,0,0,0,1,1,2,0,3,5,1,1,1,0,2,0,2,4,0,3,3,1,0,3,3,0,0,1,3,0,1,1,1,1,4,1,0,1,2,0,3,5,0,1,2,
0,2,1,1,2,0,1,0,0,2,1,2,5,1,2,0,1,0,0,1,1,0,0,0,0,3,0,2,0,0,0,2,1,0,2,1,1,0,0,0,0,1,2,0,2,1,0,0,0,1,
2,2,2,5,4,4,1,5,2,2,1,1,4,1,0,1,0,2,0,3,0,1,0,0,4,0,4,0,0,0,1,3,3,0,1,1,2,2,3,2,3,0,2,0,4,0,1,1,0,3,
0,0,0,0,0,1,0,0,0,0,0,32,24,44,27,21,32,50,23,23,55,4,10,10,16,35,9,18,36,8,37,38,48,16,42,16,32,31,
37,23,55,28,26,14,13,32,4,28,45,11,13,9,31,8,23,11,11,12,36,31,39,9,28,33,19,11,10,19,42,16,24,30,33,
22,24,24,6,33,4,9,6,26,17,4,6,4,8,9,8,8,6,4,4,5,7,9,7,7,19,1,5,4,6,9,0,6,6,6,0,9,8,5,3,5,8,9,3,5,23,7,
10,5,5,4,2,7,15,4,3,3,11,1,8,2,0,0,11,8,12,2,6,9,2,6,3,9,9,8,12,8,11,11,4,7,0,8,1,1,1,5,4,1,0,5,3,2,3),
nrow=78,ncol=4,byrow=FALSE)
rownames(disabilitas)=c('TEMON','WATES','PANJATAN','GALUR','LENDAH','SENTOLO','PENGASIH','KOKAP','GIRIMULYO','NANGGULAN','SAMIGALUH','KALIBAWANG','SRANDAKAN','
SANDEN','KRETEK','PUNDONG','BAMBANG LIPURO','PANDAK','PAJANGAN','BANTUL','
JETIS','IMOGIRI','DLINGO','BANGUNTAPAN','PLERET','PIYUNGAN','SEWON','KASIHAN','
SEDAYU','WONOSARI','NGLIPAR','PLAYEN','PATUK','PALIYAN','PANGGANG','TEPUS','SEMANU','
KARANGMOJO','PONJONG','RONGKOP','SEMIN','NGAWEN','GEDANGSARI','SAPTOSARI','
GIRISUBO','TANJUNGSARI','PURWOSARI','GAMPING','GODEAN','MOYUDAN','MINGGIR','
SEYEGAN','MLATI','DEPOK','BERBAH','PRAMBANAN','KALASAN','NGEMPLAK','NGAGLIK','
SLEMAN','TEMPEL','TURI','PAKEM','CANGKRINGAN','TEGALREJO','JETIS','GONDOKUSUMAN','
DANUREJAN','GEDONGTENGEN','NGAMPILAN','WIROBRAJAN','MANTRIJERON','KRATON','GONDOMANAN','
PAKUALAMAN','MERGANGSAN','UMBULHARJO','KOTAGEDE')
colnames(disabilitas)=c('ADK.MJ','ADK.MF','PD.MJ','PD.MF')
disabilitas
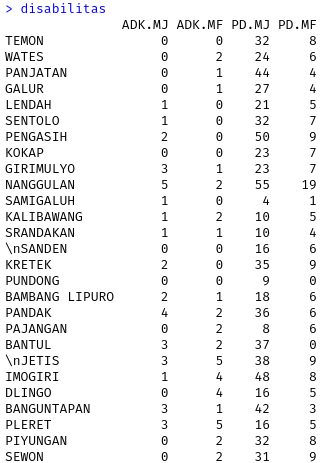
Berikut ini adalah potongan output dari input data :
Pendeteksian Outlier
Pada penelitian ini, pengujian data outlier dilakukan dengan metode grafis menggunakan software R. Berikut ini adalah syntax yang digunakan untuk deteksi outlier.
library(MVN)
hasil<- mvOutlier(disabilitas, qqplot=TRUE, method ="quan")
disabilitas_baru =hasil$newData
disabilitas_baru
Berikut ini adalah output dari
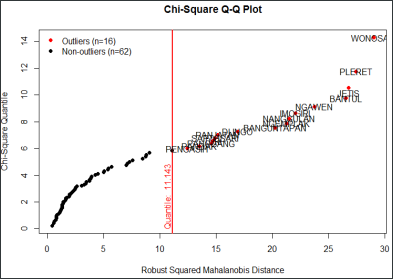
Berdasarkan output Q-Q Plotpada software R dapat diketahui bahwa data memiliki outlier sebanyak 16 dan non-outlier sebanyak 62 data. Berdasarkan hal tersebut, peneliti memutuskan untuk tidak mengikutsertakan data outlier dalam analisis cluster. Hal ini disebabkan karena jika outlier diikutsertakan dalam analisis, dapat menyebabkan hasil cluster yang kurang representatif atau tidak sesuai dengan struktur yang sebenarnya. Oleh karenanya, data outlier tersebut tidak diikutsertakan dalam analisis cluster melainkan data outlier tersebut dianalisis secara terpisah.
Pengujian Multikolinearitas
Dalam melakukan pengujian multikolinearitas, disini saya menggunakan software SPSS untuk mempercepat pengujian dengan cara sebagai berikut :
- Menginputkan data pada SPSS
- Kik analyze > regression > linear
- Memasukan seluruh variabel kedalam kolom Independent(s)
- Metode yang digunakan dapat menggunakan metode enter atau stepwise. Disini saya menggunakan metode enter . Perbedaan penggunaan metode ini dapat dilihat disini
- Klik tombol statistics kemudian centang colinearity diagnostics dan descriptives
- Untuk opsi lainnya tergantung kebutuhan peneliti
- Tekan tombol continue
- Klik OK
Berikut ini adalah output dari
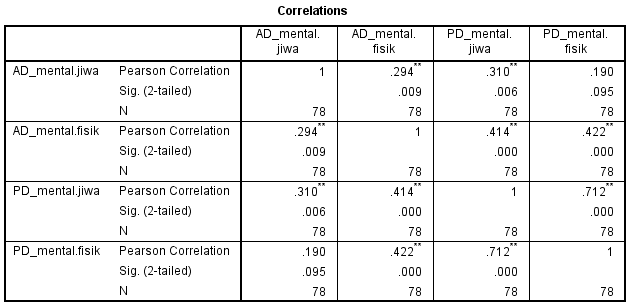
Gambar diatas merupakan hasil uji korelasi antar variabel AD mental jiwa, AD mental fisik, PD mental jiwa, dan PD mental fisik dengan bantuan software SPSS 22. Dari gambar tersebut dapat diketahui bahwa nilai korelasi pearson antar masing-masing variabel tidak ada yang melebihi 0,8. Sebagai contoh untuk variabel AD mental jiwa dengan variabel AD mental fisik memiliki nilai korelasi pearson sebesar 0,294; variabel AD mental jiwa dengan PD mental fisik memiliki nilai korelasi pearson sebesar 0,310, dan seterusnya tidak ada yang melebihi 0,8. Oleh karena itu, dapat disimpulkan bahwa tidak terjadi multikolinearitas antara variabel yang satu dengan variabel yang lain. Dengan demikian, ukuran jarak yang dapat digunakan untuk analisis cluster pada data disabilitas mental adalah ukuran jarak Euclid.
Clustering dan Profilisasi
Hasil cluster kecamatan berdasarkan AD mental jiwa, AD mental fisik, PD mental jiwa dan PD mental fisik dibagi menjadi 3 cluster dari proses pemotongan dendogram. Dalam melakukan pemotongan cluster ini, tidak ada ketentuan atau acuan mengenai jumlah cluster. Namun dalam penelitian ini, peneliti membentuk cluster menjadi 3 kelompok dengan tujuan untuk melihat wilayah mana yang memiliki disabilitas rendah, sedang, dan tinggi. Dalam menentukan kategori cluster rendah, sedang, dan tinggi dilihat dari nilai perhitungan rata-rata variabel yang tertinggi dan terendah secara keseluruhan. Berikut proses dan hasil cluster menggunakan metode average linkage, complete linkage, single linkage, ward dan centroid.
Cluster dengan Metode Average Linkage
hierarkiave<-hclust(dist(scale(disabilitas)), method="ave")
hierarkiave
windows()
plot(hierarkiave) #dendogram
rect.hclust(hierarkiave,3) #plot mengelompokkan data
anggotaave<-cutree(hierarkiave,k=3) #hasil kelompok data
anggotaave
tabulasiave<-data.frame(disabilitas,anggotaave) # hasil kelompok data dalam bentuk data frame
View(tabulasiave)
Berikut ini adalah output dendogram cluster dengan Metode Average Linkage

Berikut ini adalah output tabulasi cluster dengan Metode Average Linkage
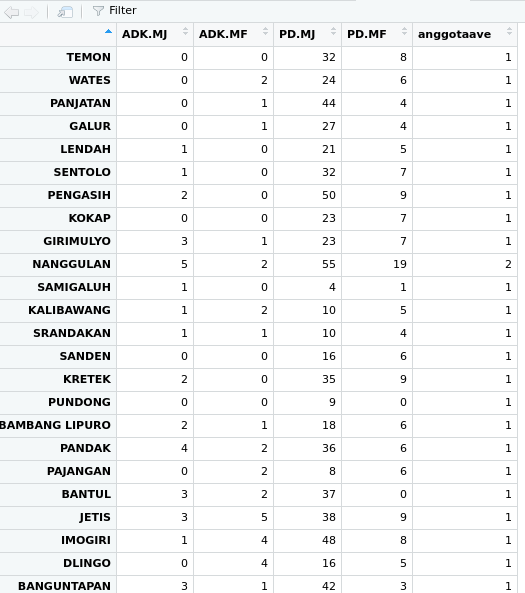
Hasil cluster dengan Metode Average Linkage tersebut kemudian dihitung rata-ratanya sehingga menghasilkan tabel seperti dibawah ini :
| Cluster | JumlahAnggota | AD mental jiwa | AD mental fisik | PD mental jiwa | PD mental fisik | Rata-rata |
|---|---|---|---|---|---|---|
| 1 (Rendah) | 36 | 1.08 | 0.58 | 12.03 | 3.44 | 4.28 |
| 2 (Sedang) | 25 | 0.64 | 1.28 | 28.68 | 7.68 | 9.57 |
| 3(Tinggi) | 1 | 1.00 | 0.00 | 45.00 | 15.00 | 15.25 |
Berdasarkan tabel diatas, dapat diketahui nilai rata-rata untuk masing-masing variabel pada masing-masing cluster sehingga dari nilai tersebut dapat dilakukan interpretasi cluster sebagai berikut:
- Cluster 1 : Cluster yang beranggotakan 36 kecamatan dimana cluster pertama memiliki rata-rata jumlah AD mental jiwa, AD mental fisik, PD mental jiwa, dan PD mental fisik dalam jumlah rendah.
- Cluster 2 : Cluster yang beranggotakan 25 kecamatan dimana cluster kedua memiliki rata-rata jumlah AD mental jiwa, AD mental fisik, PD mental jiwa, dan PD mental fisik dalam jumlah sedang.
- Cluster 3 : Cluster yang beranggotakan 1 kecamatan dimana cluster ketiga memiliki rata-rata jumlah AD mental jiwa, AD mental fisik, PD mental jiwa, dan PD mental fisik dalam jumlah tinggi.
Berikut ini adalah Hasil Anggota Cluster Metode Average Linkage
| Tingkatan Jumlah Penderita Disabilitas Mental | Anggota Cluster | |
|---|---|---|
| Rendah | Lendah, Girimulyo, Samigaluh, Kalibawang, Srandakan, Sanden, Pundong, Bambang Lipuro, Pajangan, Jetis, Sedayu, Patuk, Paliyan, Tepus, Ponjong, Rongkop, Semin, Gedangsari, Girisubo, Tanjungsari, Purwosari, Minggir, Berbah, Prambanan, Ngaglik, Danurejan, Gedongtengen, Ngampilan, Wirobrajan, Mantrijeron, Kraton, Gondomanan, Pakualaman, Mergangsan, Umbulharjo, Dan Kota Gede | |
| Sedang | Temon, Wates, Galur, Sentolo, Kokap, Kretek, Piyungan, Sewon, Kasihan, Nglipar, Playen, Semanu, Gamping, Godean, Moyudan, Seyegan, Mlati, Depok, Kalasan, Sleman, Tempel, Pakem, Cangkringan, Tegalrejo, Gondokusuman | |
| Tinggi | Karangmojo |
Untuk melakukan analisis cluster pada metode hirarki cluster lainnya menggunakan syntax yang dapat diunduh disini
Penentuan Metode Cluster Terbaik
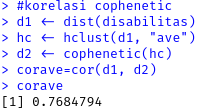
Untuk mengetahuimetode cluster terbaik dari hasil cluster yang didapat, maka dapat digunakan koefisien korelasi cophenetic, dimana jika nilai koefisien korelasi cophenetic mendekati 1 maka solusi yang dihasilkan dari proses clustering cukup baik. Nilai korelasi cophenetic dapat dituliskan dengan syntax pada software R sebagai berikut :
cophenetic(hierarkiave) #jarak cophenetic average
#korelasi cophenetic
d1 <- dist(disabilitas)
hc <- hclust(d1, "ave")
d2 <- cophenetic(hc)
corave=cor(d1, d2)
corave
Berikut ini adalah output dari korelasi cophenetic metode average linkage
Untuk melakukan korelasi cophenetic pada metode hirarki cluster lainnya menggunakan syntax yang dapat diunduh disini
Dari perhitungan korelasi cophenetic dari semua metode hirarki clustering, dperoleh nilai korelasi cophenetic sebagai berikut :
| Metode Average | Metode Complete | Metode Single | Metode Ward | Metode Centroid |
|---|---|---|---|---|
| 0.783 | 0.729 | 0.598 | 0.724 | 0.779 |
Dari tabel diatas dapat dilihat nilai korelasi cophenetic yang tertinggi adalah pada metode average sehingga dapat dikatakan metode average merupakan metode cluster yang terbaik.
Catatan : Penentuan metode cluster terbaik pada data outlier dilakukan dengan cara yang sama dengan data outlier yang sudah dipisahkan diawal setelah dilakukan pendeteksian outlier.
Penelitian lengkap dapat diunduh disini