Hierarchical Cluster Analysis Concept
Hierarchical Cluster Analysis Concept
Analisis Cluster
Analisis cluster adalah proses untuk mengelompokan suatu himpunan secara fisik atau abstrak kedalam suatu kelas objek yang memiliki kemiripan. Clustering mengelompokan objek data keobjek lainnya yang mirip dan memisahkan objek data yang tidak mirip ke cluster lainnya (Han, 2006).
Clustering berbeda dengan klasifikasi, dalam hal tidak ada variabel target untuk clustering. Menurut Larose (2004) menyatakan bahwa clustering tidak mengklasifikasikan, meramalkan, atau memprediksi nilai dari sebuah variabel target. Algoritma-algoritma clustering digunakan untuk menentukan segmen keseluruhan himpunan data menjadi subgroup yang relatif sama atau cluster, dengan kesamaan record dalam cluster dimaksimumkan dan kesamaan record di luar cluster diminimumkan.
Memilih Ukuran Jarak
Ada tiga ukuran untuk mengukur kesamaan antar objek dalam analisis yaitu ukuran asosiasi, ukuran korelasi dan ukuran kedekatan.
- Ukuran Asosiasi Menurut Simamora dalam Skripsi Laeli ukuran asosiasi biasanya dipakai untuk mengukur data berskala non metrik (nominal atau ordinal), dengan cara mengambil bentuk-bentuk dari koefisien korelasi pada tiap obyeknya, dengan memutlakkan korelasi-korelasi yang bernilai negatif (Simamora dalam Skripsi Sodya Laeli, 2014)
- Ukuran Korelasi Ukuran korelasi biasanya dipakai untuk mengukur data skala matriks, tetapi ukuran ini jarang digunakan karena titik beratnya pada nilai suatu pola tertentu, padahal titik berat analisis cluster terletak pada besarnya obyek. Kesamaan antar obyek dapat diketahui dari koefisien korelasi antar pasangan obyek yang diukur dengan menggunakan beberapa variabel (Sofya Laeli, 2014).
- Ukuran Kedekatan Ukuran kuantitatif yang menunjukkan kedekatan antar objek yang seringkali digunakan dalam konteks ini adalah ketidakmiripan (dissimilarity), jarak (distance), kemiripan (similarity); atau secara umum dikenal dengan istilah kedekatan (proximity). Dua individu dikatakan “dekat” ketika ketidakmiripan atau jarak di antara mereka kecil atau kemiripan mereka besar (Everitt, dkk., 2011:43). Ukuran kemiripan seringkali digunakan ketika semua variabel dari data yang digunakan adalah kategorik (Everitt, dkk., 2011:46). Sedangkan jika variabel dalam data adalah kontinu, maka kedekatan antar individu secara khusus diukur dengan menggunakan ukuran ketidakmiripan (dissimilarity measures) atau ukuran jarak (distance measures) (Everitt, dkk., 2011:49). Ukuran ketidakmiripan (dissimilarity measures) atau ukuran jarak (distance measures) yang paling sering digunakan untuk mengukur jarak antar objek adalah jarak Euclidean (Hair, dkk. (2010:499) & Everitt, dkk. (2011:49)).
Asumsi Cluster
Dalam melakukan analisis cluster ada beberapa hal yang perlu diperhatikan, diantaranya sebagai berikut:
Uji Outlier Menurut Ghozali (2006:41) outlier adalah kasus atau data yang memiliki karakteristik unik yang terlihat sangat berbeda jauh dari observasi-observasi lainnya dan muncul dalam bentuk nilai ekstrim baik untuk sebuah variabel tunggal atau variabel kombinasi. Ada empat penyebab timbulnya data outlier: 1. kesalahan dalam memasukkan data; 2. gagal menspesifikasikan adanya missing value dalam program komputer; 3. outlier bukan merupakan anggota populasi yang kita ambil sebagai sampel; 4. outlier berasal dari populasi yang kita ambil sebagai sampel, tetapi distribusi dari variabel dalam populasi tersebut memiliki nilai ekstrim dan tidak berdistribusi normal.
Uji No Multikolinearitas Analisis cluster harus memenuhi asumsi no-multikolinearitas yaitu tidak terdapat korelasi antar variabel, dimana untuk mengetahui asumsi tersebut terpenuhi atau tidak maka harus dilakukan pengujian asumsi no-multikolinearitas salah satunya dengan menghitung koefisien korelasi. Menurut Gujrati (1978) dalam Rahmawati, dkk (2017) gejala multikolinearitas dapat dideteksi dengan beberapa cara yaitu sebagai berikut: 1. Menghitung koefisien korelasi sederhana (simple correlation) Antara sesama variabel bebas, jika terdapat koefisien korelasi sederhana yang mencapai atau melebihi 0.8 maka terjadi multikolinearitas. (Bluman, 2004:499). 2. Menghitung nilai tolerance atau VIF, jika nilai toleransi kurang dari 0.1 atau nilai VIF melebihi 10 maka menunjukkan bahwa terjadi multikolinearitas antar variabel.
Metode Analisis Cluster
Analisis cluster terbagi menjadi dua yaitu analisis cluster hirarki dan analisis cluster non-hirarki. Metode hirerarki untuk mengelompokkan objek berdasarkan kemiripan yang ada pada objek tersebut di mana objek yang serupa akan diclusterkan bersama dan efektif digunakan untuk mengelompokkan < 100 objek. Sedangkan metode non hirerarki berguna untuk mengelompokkan sejumlah objek ke dalam jumlah cluster yang sudah ditetapkan di mana karakteristik objek hanya di-cluster-kan berdasarkan variabel tertentu akan tetapi karakteristik latar belakang objek belum diketahui pasti yang efektif jika digunakan untuk pengelompokan > 100 objek (Yamin, 2009). Klasifikasi prosedur peng-cluster-an analisis cluster ini ditampilkan dalam bagan di bawah ini (Simamora, 2005):
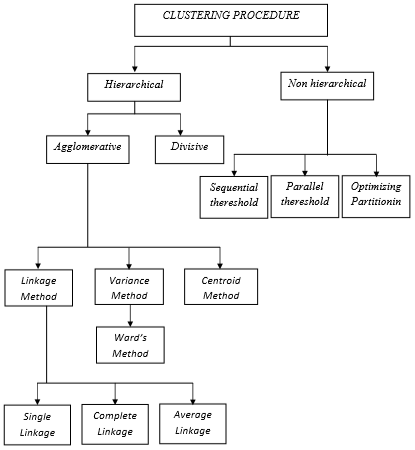 Sumber : (Laely, 2014)
Sumber : (Laely, 2014)
Metode Hierarki
Metode hierarki merupakan metode pengelompokan yang terstruktur dan bertahap berdasarkan pada kemiripan sifat antar objek. Kemiripan sifat tersebut dapat ditentukan dari kedekatan jarak. Ukuran jarak yang dapat digunakan yaitu ukuran jarak Euclid atau ukuran jarak Mahalanobis. Jarak Euclid digunakan jika tidak terjadi korelasi atau tidak terjadi multikolinearitas sementara jarak Mahalanobis digunakan jika data terjadi korelasi atau terjadi multikolinearitas (Rahmawati, 2007). Adapun metode pengelompokkan cluster hierarki yaitu:
Metode Agglomerative
Metode agglomeratif dimulai dengan menganggap bahwa setiap obyek adalah sebuah cluster. Kemudian dua obyek dengan jarak terdekat digabungakan menjadi satu cluster. Selanjutnya obyek ketiga akan bergabung dengan cluster yang ada atau bersama obyek lain dan membentuk cluster baru dengan tetap memperhitungkan jarak kedekatan antar obyek. Proses akan berlanjut hingga akhirnya terbentuk satu cluster yang terdiri dari keseluruhan obyek. Metode aglomeratif sendiri masih ada beberapa macam, yaitu :
- Single-linkage (pautan tunggal), metode dengan prinsip jarak minimum. Metode single linkage adalah metode cluster dimana objek diclusterkan berdasarkan jarak minimum atau jarak terdekat antar objek. Dua objek yang mempunyai jarak yang paling dekat akab di-cluster-kan menjadi satu cluster dan hal ini terus dilakukan hingga semua objek membentuk satu cluster. Langkah-langkah menggunakan metode single linkage (Johnson & Wichern, 1992): a. Menemukan jarak minimum dalam D = {dij} b. Menghitung jarak antara cluster yang telah dibentuk pada langkah 1 dengan obyek lainnya. c. Dari algoritma di atas jarak-jarak antara (ij) dan cluster k yang lain dihitung Dalam hal ini besaran-besaran dan masing-masing adalah jarak terpendek antara cluster-cluster i dan k dan juga cluster-cluster j dan k.
- Complete linkage (pautan lengkap) Metode complete linkage ini merupakan kebalikan dari metode single linkage dimana pada metode complete linkage proses clustering berdasarkan pada jarak maksimum/jarak terjauh antar objek. Algortima metode complete linkage dimulai dengan menemukan elemen minimum dalam D = {dij}, selanjutnya menggabungkan objek-objek yang bersesuaian misalnya U dan V untuk mendapatkan cluster (UV). Tahap berikutnya, jarak di Antara (UV) dan cluster lainnya, misalnya W. (Johnson & Wichern, 2007:686)
- Average-linkage (pautan rata-rata) Average linkage merupakan variasi dari algoritma single linkage dan complete linkage yaitu menghitung jarak antara dua cluster yang disebut sebagai jarak rata-rata dimana jarak tersebut dihitung pada masing-masing cluster dengan meminimumkan rata-rata jarak antara pasangan cluster yang digabungkan. Metode umum dimulai penemuan anggota lain pada D = {dik} dan menggabungkan obyek yang berkorespondensi misalnya U dan V menjadi (UV). (Johnson dan Wichern, 1992)
- Ward’s method Metode ini ini menggunakan perhitungan yang lengkap dan memaksimumkan homogenitas di dalam satu cluster. (Dillon & Goldstein, 1984)
- Centroid method (metode titik pusat) Metode centroid adalah metode yang menggunakan rata-rata jarak pada sebuah cluster yang diperoleh dengan cara menghitung rata-rata pada setiap variabel untuk semua objek. Dengan metode ini, setiap terjadi cluster baru segera terjadi perhitungan ulang centroid sampai terbentuk cluster yang tetap (Sokal & Michener, 1958 dalam Seber, 1984).
Metode Divisive
Proses dalam metode divisif berkebalikan dengan metode agglomerative. Metode ini dimulai dengan satu cluster besar yang mencakup semua objek pengamatan. Selanjutnya, secara bertahap objek yang mempunyai ketidakmiripan cukup besar akan dipisahkan ke dalam cluster-cluster yang berbeda. Proses dilakukan sehingga terbentuk sejumlah cluster yang diinginkan, seperti, dua cluster, tiga cluster, dan seterusnya.
Metode Non Hierarki
Metode non hierarki sering disebut sebagai metode k-means. Prosedur pada metode non hierarki dimulai dengan memilih sejumlah nilai cluster awal sesuai dengan jumlah yang diinginkan, kemudian obyek pengamatan digabungkan ke dalam cluster-cluster tersebut. Metode non hierarki ini meliputi metode sequential threshold, parallel threshold, dan optimizing partitioning (Gudono, 2011).
- Metode Sequential Threshold Pada metode Sequential Threshold dimulai dengan pemilihan satu cluster dan menempatkan semua obyek yang berada pada jarak terdekat ke dalam cluster tersebut. Jika semua obyek yang berada pada ambang batas tertentu telah dimasukkan, kemudian cluster yang kedua dipilih dan menempatkan semua obyek yang berada pada jarak terdekat ke dalamnya. Kemudian cluster ketiga dipilih dan proses dilanjutkan seperti yang sebelumnya.
- Metode Parallel Threshold Secara prinsip sama dengan metode sequential threshold, hanya saja pada metode parallel threshold dilakukan pemilihan terhadap beberapa obyek awal cluster sekaligus dan kemudian melakukan penggabungan obyek ke dalamnya secara bersamaan. Pada saat proses berlangsung, jarak terdekat dapat ditentukan untuk memasukkan beberapa obyek ke dalam cluster-cluster.
- Metode Optimization Metode Optimization hampir mirip dengan metode Sequential Threshold dan metode Parallel Threshold yang membedakan adalah metode optimization ini memungkinkan untuk menempatkan kembali obyek-obyek ke dalam cluster yang lebih dekat atau dengan melakukan optimasi pada penempatan obyek yang ditukar untuk cluster lainnya dengan pertimbangan kriteria optimasi.
Menentukan Banyaknya Cluster
Masalah utama dalam analisis cluster ialah menetukan berapa banyaknya cluster. Sebetulnya tidak ada aturan yang baku untuk menentukan berapa sebetulnya banyaknya cluster, namun demikian ada beberapa petunjuk yang bisa dipergunakan, yaitu (Supranto, 2004):
- Pertimbangan teoretis, konseptual, praktis, mungkin bisa diusulkan/disarankan untuk menetukan berapa banyaknya cluster yang sebenarnya. Sebagai contoh, kalau tujuan pengclusteran untuk mengenali/mengidentifikasi segmen pasar, manajemen mungkin menghendaki cluster dalam jumlah tertentu (katakan 3, 4, atau 5 cluster).
- Besarnya relatif cluster seharusnya berguna/bermanfaat.
Uji Validitas Cluster
Setelah mendapatkan hasil dari proses cluster maka selanjutnya harus dilakukan uji validitas cluster. Uji validitas cluster diperlukan untuk melihat kebaikan (goodness) atau kualitas (quality) hasil analisis cluster. Ukuran yang digunakan untuk menguji validitas hasil clustering pada penelitian ini adalah koefisien korelasi cophenetic. Koefisien korelasi cophenetic merupakan koefisien korelasi antara elemen-elemen asli matriks ketidakmiripan (matriks jarak Euclidian) dan elemen-elemen yang dihasilkan oleh dendogran (matriks cophenetic) (Silva & Dias, 2013:589-590). Nilai rCoph berkisar antara −1 dan 1, nilai rCoph mendekati 1 berarti solusi yang dihasilkan dari proses clustering baik. Jarak cophenetic adalah jarak elemen-elemen yang dihasilkan oleh dendogram. Untuk mendapatkan jarak cpohenetic antara objek i dan k maka dilihat dari tinggi dendogram dimana kedua objek itu pertama kali bersatu. Penjelasannya bisa dilihat pada gambar dibawah:
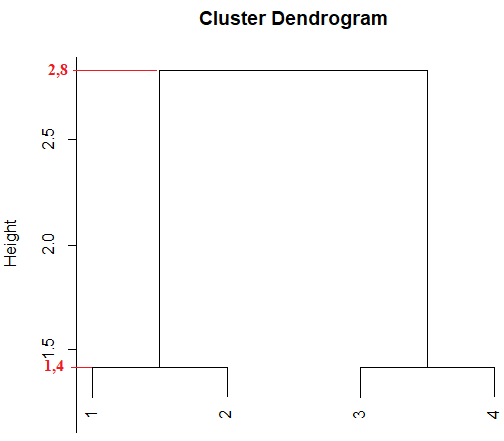 Sumber : Saraceli, 2013
Sumber : Saraceli, 2013
Berdasarkan Gambar diatas, untuk mencari jarak cophenetic dari objek 1 dan 2 maka bisa dilihat dari tinggi dendogram dimana kedua objek tersebut pertama kali bersatu yaitu 1.4, sedangkan jarak cophenetic untuk objek 2 dan 3 berdasarkan tinggi dendogram adalah 2.8.